

Copyright (C) 2025 Keerthana Purushotham <keep.consult@proton.me>.
Licensed under the GNU AGPL v3. See LICENSE for details.
To cite, scroll to the bottom or go to Github.
In cybersecurity, mapping vulnerabilities (CVEs) across Linux distributions is not just classification — it’s risk control. Whether python-requests in Debian matches python3-requests in Red Hat can mean the difference between a patched system and an exploitable one.
Why does this matter?
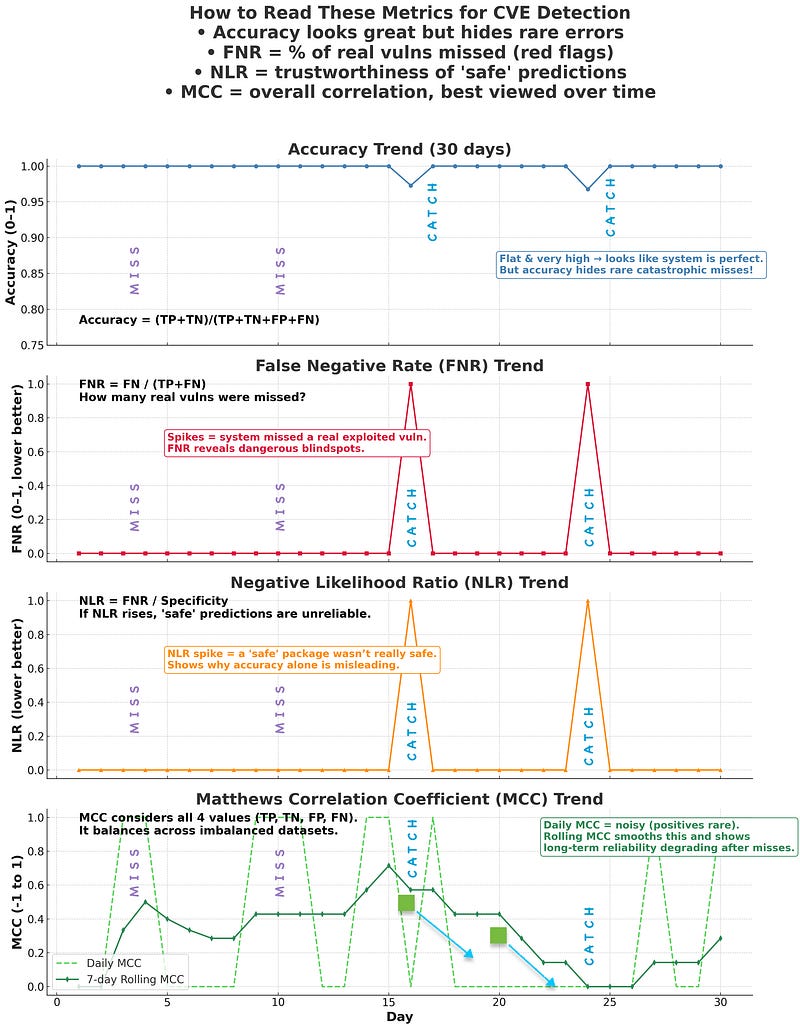
False negatives (missed vulnerabilities) leave blind spots. False positives (over-flagged safe packages) burn developer time and erode trust. Accuracy hides both problems.
The solution: treat the confusion matrix as a toolbox — and climb through its metrics step by step.
")
Trade-Offs:
👉🏽 False Negatives
The cost of not only missing the goal but also causes loss that can end in catastrophe. (e.g. market anomaly/ 0-day CVE miss, sepsis undetected until too late, or a missed satellite collision that wipes out a B$ asset. That’s why systems go heavy on redundancy, richer signals & constant error analysis to catch what matters most.)
👉🏽 False Positives
Less risk, but they kill trust/efficiency. Too many false alarms=alert fatigue, labor etc(eg:trade-entries falsely flagged as fraud, too many SRE TTs,AV braking on empty roads, false debris alarms[i.e fuel waste]- in space. Even justice systems suffer from facial recognition, to wrong risk scores disrupting real lives).
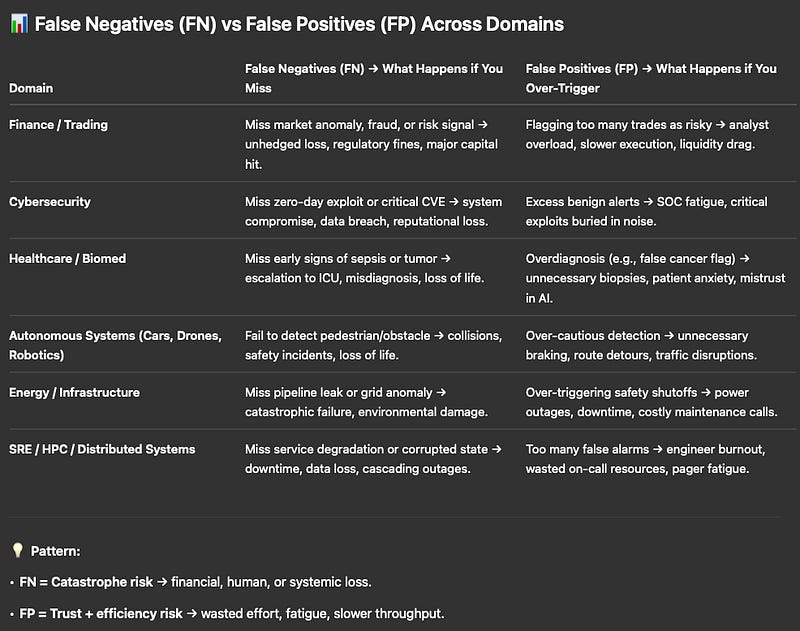
Both matter: FN kill you outright, FP bleed you slowly. Domain awareness is 🔑.

Level 0: Core Counts (Primitives)
The foundation of all metrics:
TP (True Positive): Vulnerable package correctly flagged
TN (True Negative): Safe package correctly ignored
FP (False Positive): Safe package wrongly flagged
FN (False Negative): Vulnerable package missed
Level 1: Class Rates (per positive/negative)
⭆ Recall: Prioritizes catching vulnerabilities. In security, recall is mission-critical.
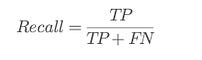
⭆ Specificity (TNR): Ensures safe packages aren’t over-flagged.
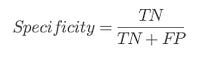
Complements:
⇒ FNR = 1 — Recall
⇒ FPR = 1 — Specificity
Security takeaway: FNR is the costliest error. FPR is the loudest error.
Level 2: Predictive Values (per outcome)
⭆ Precision (PPV): How often a flagged package is truly vulnerable.
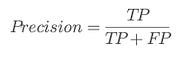
⭆ Negative Predictive Value (NPV): Measures how often a safe-labeled package is truly safe.
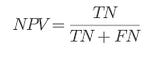
Complements:
⇒ FDR = 1 — Precision
⇒ FOR = 1 — NPV
Security takeaway: FOR is underused but vital — it tells you the risk of trusting a “safe” prediction.
Level 3: Likelihood Ratios (decision-level odds)
⭆ Positive Likelihood Ratio (PLR): How much a positive result raises odds of vulnerability.
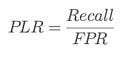
⭆ Negative Likelihood Ratio (NLR): How much a negative result lowers odds of vulnerability.
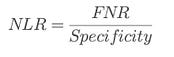
> Security takeaway: PLR = alert trustworthiness. NLR = safe decision trustworthiness.
Level 4: Balanced Metrics (threshold trade-offs)
⭆ F1-Positive: Balances catching vulnerabilities with avoiding wasted alerts.
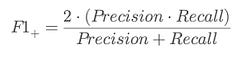
⭆ F1-Negative: Balances suppressing false alarms with maintaining trust.
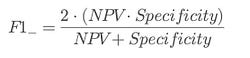
⭆ Balanced Accuracy (BA): Reduces bias in imbalanced datasets.
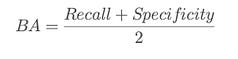
⭆ Youden’s J: Quick threshold selector maximizing separation from randomness.
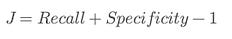
Level 5: Agreement and Global Correlation
⭆ Cohen’s Kappa (κ): Useful for proving reliability across noisy datasets.
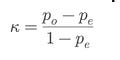
where:
⇒ pₒ = observed agreement
⇒ pₑ = expected agreement by chance
⭆ Matthews Correlation Coefficient (MCC): Gold-standard robustness metric. Stable under imbalance and interpretable across security, bioinformatics, and finance.
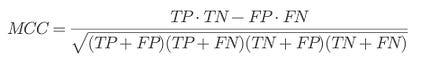
Level 6: Baseline Snapshot
⭆ Accuracy: A quick overall number — but misleading when vulnerabilities are rare.
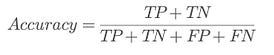
Security takeaway: Accuracy is for dashboards, not risk decisions.
Practical Recommendations
Lead with Recall and FNR — because misses are catastrophic
Track FOR and NLR — because “safe” predictions must be safe
Use Balanced Accuracy and Youden’s J — to set thresholds
Report MCC and F1 — for global robustness
Treat Accuracy — as a top-line sanity check only
Closing
Security & threat impact prediction is not about being “mostly right”. It’s about being “right where it counts”.
This leveled framework turns the confusion matrix into a decision-making map — one that reduces blind spots, manages operational noise, and builds confidence that predictions are aligned with real-world risk.
Glossary of Acronyms
1. CVE [Common Vulnerabilities and Exposures]: standardized list of publicly disclosed cybersecurity vulnerabilities.
2. TP [True Positive]: vulnerable package correctly identified as vulnerable.
3. TN [True Negative]: safe package correctly identified as safe.
4. FP [False Positive]: safe package incorrectly flagged as vulnerable.
5. FN [False Negative]: vulnerable package incorrectly classified as safe (the most costly mistake in security).
6. TPR [True Positive Rate / Recall / Sensitivity]: proportion of vulnerabilities correctly identified.
7. TNR [True Negative Rate / Specificity]: proportion of safe packages correctly ignored.
8. FNR [False Negative Rate]: proportion of vulnerabilities missed; complement of Recall.
9. FPR [False Positive Rate]: proportion of safe packages incorrectly flagged; complement of Specificity.
10. PPV [Positive Predictive Value / Precision]: proportion of flagged items that are truly vulnerable.
11. NPV [Negative Predictive Value]: proportion of safe-labeled items that are truly safe.
12. FDR [False Discovery Rate]: proportion of flagged positives that are actually false; complement of Precision.
13. FOR [False Omission Rate]: proportion of negative predictions that are actually false; complement of NPV.
14. PLR [Positive Likelihood Ratio]: how much more likely a positive prediction indicates vulnerability.
15. NLR [Negative Likelihood Ratio]: how much less likely a negative prediction indicates vulnerability.
16. BA [Balanced Accuracy]: average of Recall and Specificity, mitigating bias in imbalanced data.
17. MCC [Matthews Correlation Coefficient]: correlation-style metric incorporating all four confusion matrix elements (TP, TN, FP, FN).
18. κ [Cohen’s Kappa]: chance-corrected measure of agreement between predictions and ground truth.
 Metrics table/cheat-sheet image")
They’re all metrics that are easy to map with ingestion tools too — niche statistics you’d commonly see around ML models but mathematically speaking, they apply to any statistically, predictive black box.
For example,
CVE-2023–48022 is an epitome of how a disputed CVE turned into a false-negative, hiding an actively exploited bug downstream. Tracking False-Negative-Rate (FNR) or Negative-Likelihood-Ratio (NLR) would’ve flagged very early on that “safe/unaffected” wasn’t safe. Even MCC would’ve exposed the imbalance of missing rare but critical vulnerabilities.
The JSON for OSV template has attributes that can be automated,
- CNA [disputed] → implying no urgent fix needed.
- CISA [affected] → treat as dangerous.
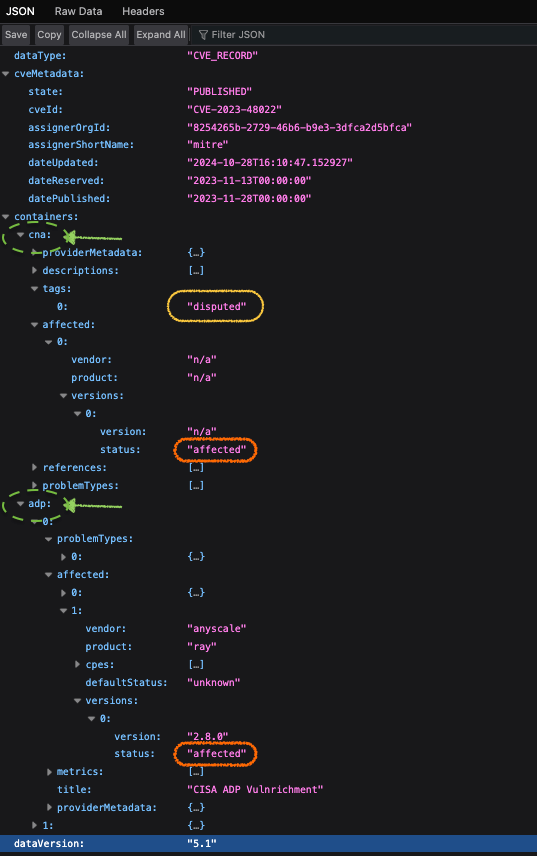
That’s the FN suppressed incorrectly when it was being actively exploited.
- FNR (↑) spikes to 1 if an exploited vulnerability is missed.
- NLR (↑) the “safe/unaffected” label was untrustworthy.
- MCC (↓) correlation drops since a rare but critical positive was missed.
But all this obviously depends on the timing of & if exploitations/bugs in your tool are identifiable.
To help visualize the dashboard, I plotted a sample and it would look something like this — [image attached below].
References
What is a Confusion Matrix? | Machine Learning Glossary | Encord | Encord
What is a confusion matrix? What is the accuracy of the confusion matrix? What is the confusion matrix for detection…encord.com
F1 Score in Machine Learning
A comprehensive guide to F1 score in Machine Learning. From understanding its calculation to interpreting results and…encord.com
Jaccard index — Wikipedia
The Jaccard index is a statistic used for gauging the similarity and diversity of sample sets. It is defined in general…en.wikipedia.org
DamerauLevenshtein can be extended from char-strings to set-lvl comparisons for similarity match across full lists instead of tokens only.
Damerau-Levenshtein distance — Wikipedia
In information theory and computer science, the Damerau-Levenshtein distance (named after Frederick J. Damerau and…en.wikipedia.org
Approximate string matching — Wikipedia
In computer science, approximate string matching (often colloquially referred to as fuzzy string searching) is the…en.wikipedia.org
Fuzzy logic — Wikipedia
Fuzzy logic is a form of many-valued logic in which the truth value of variables may be any real number between 0 and…en.wikipedia.org
Cite this article -
( github.com/keerthanap8898/Accuracy-is-Not-Enough-in-Cybersecurity )
APA (7th Edition):
Purushotham, K. (2024, [Month Day]). Accuracy is not enough: Confusion matrix metrics that actually work in CVE impact prediction. [Substack: keerthanapurushotham.substack.com/p/accuracy-is-not-enough-confusion](https://keerthanapurushotham.substack.com/p/accuracy-is-not-enough-confusion) Also available at: [Medium](https://medium.com/@keerthanapurushotham/accuracy-is-not-enough-confusion-matrix-metrics-that-actually-work-in-cve-impact-prediction-d4bafd9cec1b) [GitHub](https://github.com/keerthanap8898/Accuracy-is-Not-Enough-in-Cybersecurity/tree/main)
IEEE Style :
K. Purushotham, “Accuracy Is Not Enough: Confusion Matrix Metrics That Actually Work in CVE Impact Prediction,” Substack, Oct. 2024. [Open-source on Substack: keerthanapurushotham.substack.com/p/accuracy-is-not-enough-confusion](https://keerthanapurushotham.substack.com/p/accuracy-is-not-enough-confusion) Also available at: [Medium](https://medium.com/@keerthanapurushotham/accuracy-is-not-enough-confusion-matrix-metrics-that-actually-work-in-cve-impact-prediction-d4bafd9cec1b) [GitHub](https://github.com/keerthanap8898/Accuracy-is-Not-Enough-in-Cybersecurity/tree/main)
BibTex Entry :
```bibtex @misc{purushotham2024accuracy, author = {Keerthana Purushotham}, title = {Accuracy Is Not Enough: Confusion Matrix Metrics That Actually Work in CVE Impact Prediction}, howpublished = {Substack}, year = {2024}, month = {October}, url = {https://keerthanapurushotham.substack.com/p/accuracy-is-not-enough-confusion}, note = {Also available on Medium and GitHub: \url{https://medium.com/@keerthanapurushotham/accuracy-is-not-enough-confusion-matrix-metrics-that-actually-work-in-cve-impact-prediction-d4bafd9cec1b}, \url{https://github.com/keerthanap8898/Accuracy-is-Not-Enough-in-Cybersecurity}} } ```